NSGA-III#
The algorithm is implemented based on [27] [28]. Implementation details of this algorithm can be found in [29]. NSGA-III is based on Reference Directions which need to be provided when the algorithm is initialized.
First, the non-dominated sorting is done as in NSGA-II for survival.
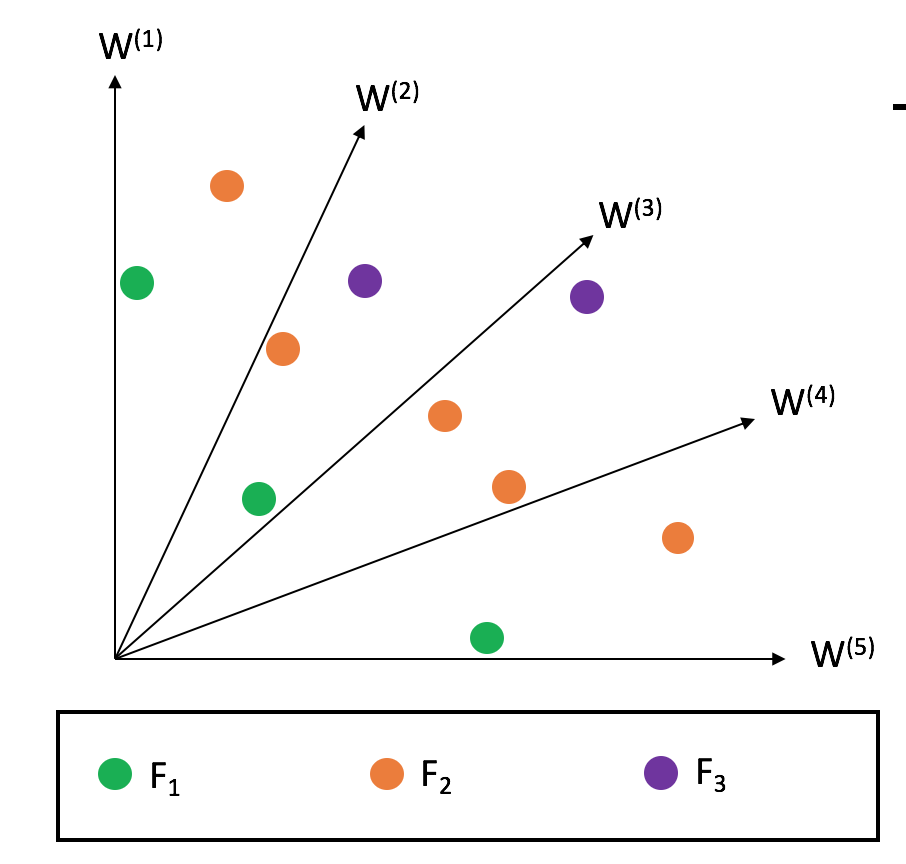
Second, from the splitting front, some solutions need to be selected. NSGA-III fills up the underrepresented reference direction first. If the reference direction does not have any solution assigned, then the solution with the smallest perpendicular distance in the normalized objective space is surviving. In case a second solution for this reference line is added, it is assigned randomly.
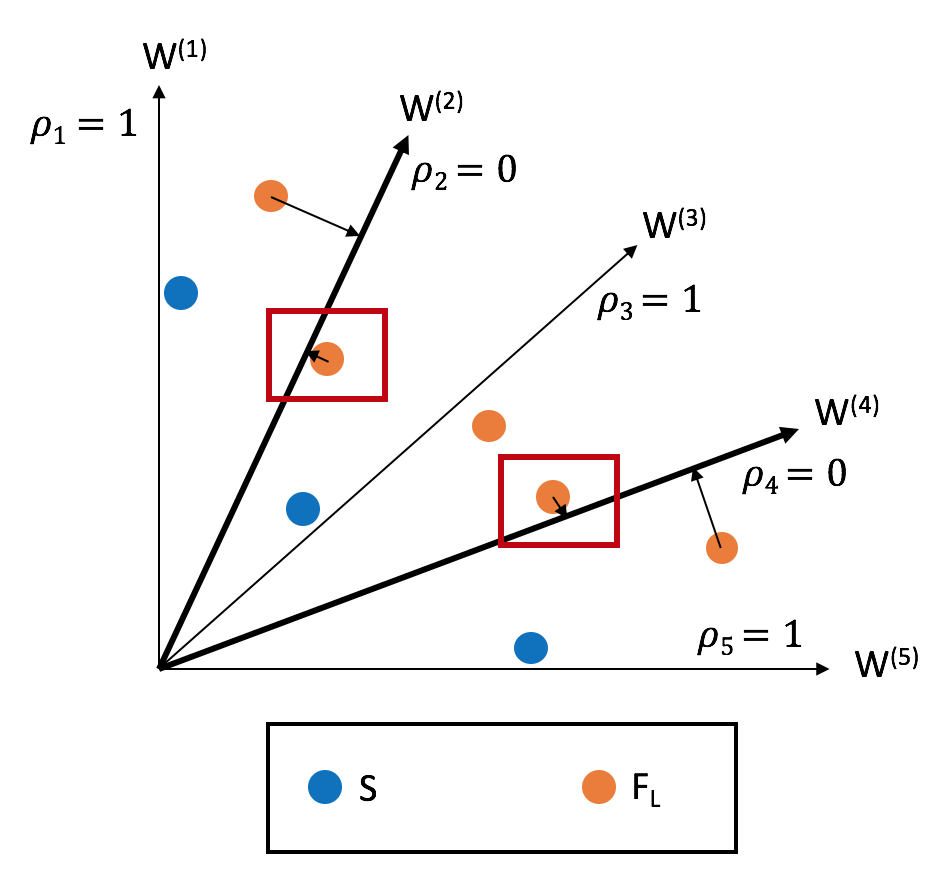
Thus, when this algorithm converges, each reference line seeks to find a good representative non-dominated solution.
Example#
[1]:
from pymoo.algorithms.moo.nsga3 import NSGA3
from pymoo.optimize import minimize
from pymoo.problems import get_problem
from pymoo.util.ref_dirs import get_reference_directions
from pymoo.visualization.scatter import Scatter
# create the reference directions to be used for the optimization
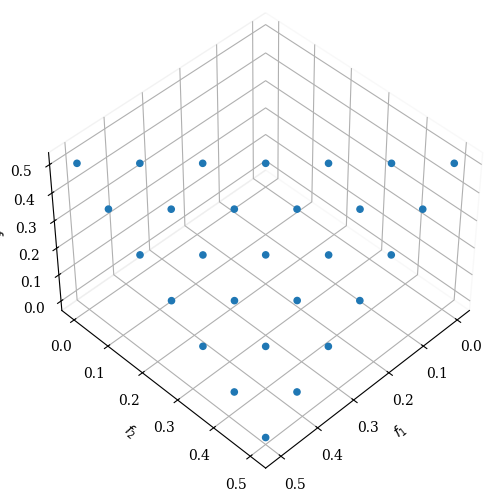
ref_dirs = get_reference_directions("das-dennis", 3, n_partitions=12)
# create the algorithm object
algorithm = NSGA3(pop_size=92,
ref_dirs=ref_dirs)
# execute the optimization
res = minimize(get_problem("dtlz1"),
algorithm,
seed=1,
termination=('n_gen', 600))
Scatter().add(res.F).show()
[1]:
<pymoo.visualization.scatter.Scatter at 0x7b110a922550>
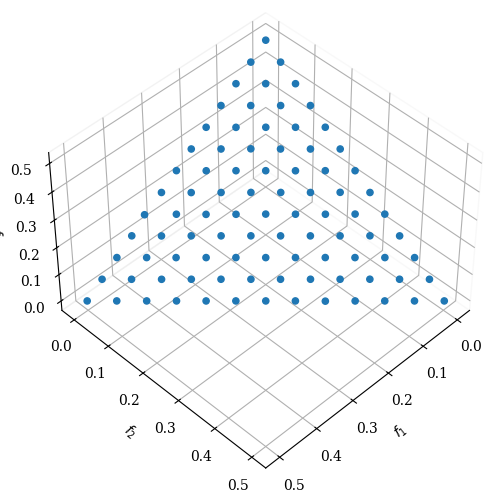
[2]:
res = minimize(get_problem("dtlz1^-1"),
algorithm,
seed=1,
termination=('n_gen', 600))
Scatter().add(res.F).show()
[2]:
<pymoo.visualization.scatter.Scatter at 0x7b114c0a59d0>