U-NSGA-III#
The algorithm is implemented based on [30]. NSGA-III selects parents randomly for mating. It has been shown that tournament selection performs better than random selection. The U stands for unified and increases NSGA-III’s performance by introducing tournament pressure.
The mating selection works as follows:

Example#
[1]:
import numpy as np
from pymoo.algorithms.moo.nsga3 import NSGA3
from pymoo.algorithms.moo.unsga3 import UNSGA3
from pymoo.problems import get_problem
from pymoo.optimize import minimize
problem = get_problem("ackley", n_var=30)
# create the reference directions to be used for the optimization - just a single one here
ref_dirs = np.array([[1.0]])
# create the algorithm object
algorithm = UNSGA3(ref_dirs, pop_size=100)
# execute the optimization
res = minimize(problem,
algorithm,
termination=('n_gen', 150),
save_history=True,
seed=1)
print("UNSGA3: Best solution found: \nX = %s\nF = %s" % (res.X, res.F))
UNSGA3: Best solution found:
X = [-0.01452247 0.10488671 -0.05554308 -0.15282582 0.07108663 -0.00474762
0.03998208 -0.16357624 -0.03409419 -0.034674 -0.05350105 -0.07683928
-0.0294493 0.03797795 -0.03061699 -0.02951845 -0.03778558 -0.02335115
0.07986168 -0.04592675 -0.01191177 -0.02108846 0.03165472 -0.1141958
0.00033753 -0.04114211 -0.00800433 0.09807808 -0.00910689 -0.01033059]
F = [0.45634742]
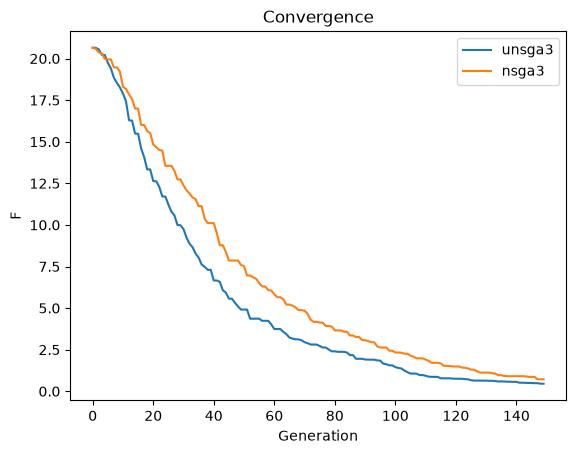
U-NSGA-III has for single- and bi-objective problems a tournament pressure which is known to be useful. In the following, we provide a quick comparison (here just one run, so not a valid experiment) to see the difference in convergence.
[2]:
_res = minimize(problem,
NSGA3(ref_dirs, pop_size=100),
termination=('n_gen', 150),
save_history=True,
seed=1)
print("NSGA3: Best solution found: \nX = %s\nF = %s" % (res.X, res.F))
NSGA3: Best solution found:
X = [-0.01452247 0.10488671 -0.05554308 -0.15282582 0.07108663 -0.00474762
0.03998208 -0.16357624 -0.03409419 -0.034674 -0.05350105 -0.07683928
-0.0294493 0.03797795 -0.03061699 -0.02951845 -0.03778558 -0.02335115
0.07986168 -0.04592675 -0.01191177 -0.02108846 0.03165472 -0.1141958
0.00033753 -0.04114211 -0.00800433 0.09807808 -0.00910689 -0.01033059]
F = [0.45634742]
[3]:
import numpy as np
import matplotlib.pyplot as plt
ret = [np.min(e.pop.get("F")) for e in res.history]
_ret = [np.min(e.pop.get("F")) for e in _res.history]
plt.plot(np.arange(len(ret)), ret, label="unsga3")
plt.plot(np.arange(len(_ret)), _ret, label="nsga3")
plt.title("Convergence")
plt.xlabel("Generation")
plt.ylabel("F")
plt.legend()
plt.show()