SMS-EMOA: Multiobjective selection based on dominated hypervolume#
The algorithm is implemented based on [36]. The hypervolume measure (or s-metric) is a frequently applied quality measure for comparing the results of evolutionary multiobjective optimization algorithms (EMOAs).
SMS-EMOA aims to maximize the dominated hypervolume within the optimization process. It features a selection operator based on the hypervolume measure combined with the concept of non-dominated sorting. As a result, the algorithm’s population evolves to a well-distributed set of solutions, focusing on interesting regions of the Pareto front.
Info
Exact hypervolume contributions are used for up to 5 objectives (via moocore). For more than 5 objectives, an approximation is used automatically.
Example#
[1]:
from pymoo.algorithms.moo.sms import SMSEMOA
from pymoo.optimize import minimize
from pymoo.problems import get_problem
from pymoo.visualization.scatter import Scatter
problem = get_problem("zdt1")
algorithm = SMSEMOA()
res = minimize(problem,
algorithm,
('n_gen', 200),
seed=1,
verbose=False)
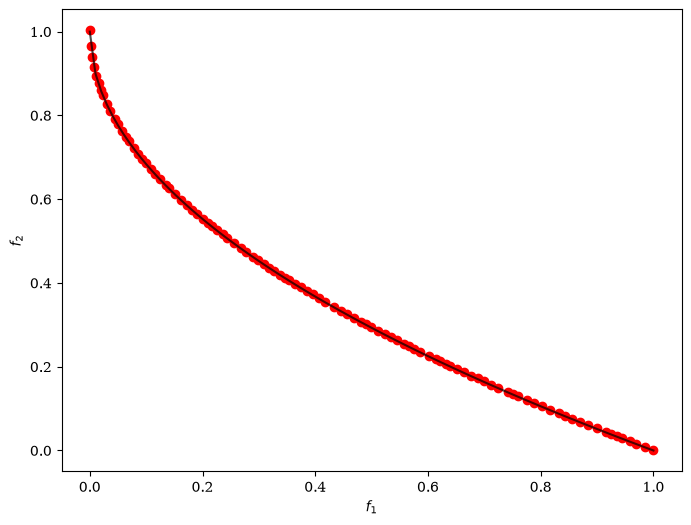
plot = Scatter()
plot.add(problem.pareto_front(), plot_type="line", color="black", alpha=0.7)
plot.add(res.F, color="red")
plot.show()
[1]:
<pymoo.visualization.scatter.Scatter at 0x739f5dd12590>