RVEA: Reference Vector Guided Evolutionary Algorithm#
The algorithm is implemented based on [35]. In RVEA, a scalarization approach, termed angle penalized distance (APD), is adopted to balance the convergence and diversity of the solutions in the high-dimensional objective space. Furthermore, an adaptation strategy is proposed to dynamically adjust the reference vectors’ distribution according to the objective functions’ scales. An illustration of the APD is shown below:

Example#
Info
Note that the APD is adapted based on the progress the algorithm has made. Thus, termination criteria such as n_gen or n_evals should be used.
[1]:
from pymoo.algorithms.moo.rvea import RVEA
from pymoo.optimize import minimize
from pymoo.problems import get_problem
from pymoo.util.ref_dirs import get_reference_directions
from pymoo.visualization.scatter import Scatter
problem = get_problem("dtlz1", n_obj=3)
ref_dirs = get_reference_directions("das-dennis", 3, n_partitions=12)
algorithm = RVEA(ref_dirs)
res = minimize(problem,
algorithm,
termination=('n_gen', 400),
seed=1,
verbose=False)
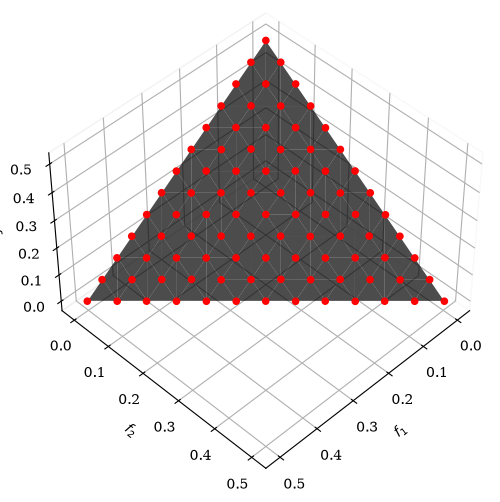
plot = Scatter()
plot.add(problem.pareto_front(ref_dirs), plot_type="surface", color="black", alpha=0.7)
plot.add(res.F, color="red")
plot.show()
[1]:
<pymoo.visualization.scatter.Scatter at 0x7a7577f03ad0>