Karush Kuhn Tucker Proximity Measure (KKTPM)#
In 2016, Deb and Abouhawwash proposed Karush Kuhn Tucker Proximity Measure (KKTPM) [57], a metric that can measure how close a point is from being “an optimum”. The smaller the metric, the closer the point. This does not require the Pareto front to be known, but the gradient information needs to be approximated. Their metric applies to both single objective and multi-objective optimization problems.
In a single objective problem, the metric shows how close a point is from being a “local optimum”, while in multi-objective problems, the metric shows how close a point is from being a “local Pareto point”. Exact calculations of KKTPM for each point requires solving a whole optimization problem, which is extremely time-consuming. To avoid this problem, the authors of the original work again proposed several approximations to the true KKTPM, namely Direct KKTPM, Projected KKTPM, Adjusted KKTPM, and Approximate KKTPM. Approximate KKTPM is simply the average of the former three and is what we call simply “KKTPM”. Moreover, they were able to show that Approximate KKTPM is reliable and can be used in place of the exact one [58].
Let us now see how to use pymoo to calculate the KKTPM for a point:
[1]:
from pymoo.constraints.from_bounds import ConstraintsFromBounds
from pymoo.gradient.automatic import AutomaticDifferentiation
from pymoo.problems import get_problem
problem = AutomaticDifferentiation(ConstraintsFromBounds(get_problem("zdt1", n_var=30)))
For instance, the code below calculates the KKTPM metric for randomly sampled points for the given example:
[2]:
from pymoo.indicators.kktpm import KKTPM
from pymoo.operators.sampling.rnd import FloatRandomSampling
X = FloatRandomSampling().do(problem, 100).get("X")
kktpm = KKTPM().calc(X, problem)
Moreover, a whole run of a genetic algorithm can be analyzed by storing each generation’s history and then calculating the KKTPM metric for each of the points:
[3]:
from pymoo.algorithms.moo.nsga2 import NSGA2
from pymoo.problems import get_problem
from pymoo.optimize import minimize
from pymoo.visualization.scatter import Scatter
from pymoo.core.evaluator import Evaluator
algorithm = NSGA2(pop_size=60, eliminate_duplicates=True)
# make sure each evaluation also has the derivatives - necessary for KKTPM
evaluator = Evaluator(evaluate_values_of=["F", "G", "dF", "dG"])
res = minimize(problem,
algorithm,
('n_gen', 50),
evaluator=evaluator,
seed=1,
save_history=True,
verbose=False)
[4]:
import pandas as pd
import numpy as np
# Collect KKTPM data for each generation
data = []
for algorithm in res.history:
if algorithm.n_gen % 5 == 0:
X = algorithm.pop.get("X")
kktpm = KKTPM().calc(X, problem)
# Add each individual's KKTPM value with generation info
for i, value in enumerate(kktpm):
data.append({
'generation': algorithm.n_gen,
'individual': i,
'kktpm': value
})
# Create DataFrame
df = pd.DataFrame(data)
df
[4]:
| generation | individual | kktpm | |
|---|---|---|---|
| 0 | 5 | 0 | 0.679958 |
| 1 | 5 | 1 | 0.748212 |
| 2 | 5 | 2 | 0.684728 |
| 3 | 5 | 3 | 0.449819 |
| 4 | 5 | 4 | 0.719930 |
| ... | ... | ... | ... |
| 595 | 50 | 55 | 0.094219 |
| 596 | 50 | 56 | 0.117224 |
| 597 | 50 | 57 | 0.118253 |
| 598 | 50 | 58 | 0.151656 |
| 599 | 50 | 59 | 0.095250 |
600 rows × 3 columns
[5]:
# Get summary statistics for each generation
stats_by_gen = df.groupby('generation')['kktpm'].describe()
stats_by_gen
[5]:
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| generation | ||||||||
| 5 | 60.0 | 0.603528 | 0.095839 | 0.449819 | 0.539470 | 0.595308 | 0.671382 | 0.815751 |
| 10 | 60.0 | 0.504904 | 0.112957 | 0.327993 | 0.387698 | 0.491648 | 0.615389 | 0.685516 |
| 15 | 60.0 | 0.381326 | 0.088071 | 0.184355 | 0.319498 | 0.360460 | 0.465261 | 0.538543 |
| 20 | 60.0 | 0.288701 | 0.080699 | 0.124784 | 0.239424 | 0.262852 | 0.338762 | 0.449536 |
| 25 | 60.0 | 0.237221 | 0.067296 | 0.026559 | 0.196161 | 0.245601 | 0.273652 | 0.366795 |
| 30 | 60.0 | 0.194723 | 0.054738 | 0.018697 | 0.164773 | 0.176872 | 0.236863 | 0.306723 |
| 35 | 60.0 | 0.166840 | 0.044275 | 0.014808 | 0.148363 | 0.157289 | 0.185268 | 0.254366 |
| 40 | 60.0 | 0.147187 | 0.038368 | 0.012130 | 0.129129 | 0.138859 | 0.168511 | 0.222903 |
| 45 | 60.0 | 0.131630 | 0.041127 | 0.002916 | 0.115029 | 0.124054 | 0.154456 | 0.216711 |
| 50 | 60.0 | 0.120393 | 0.034876 | 0.002432 | 0.104268 | 0.113240 | 0.146404 | 0.204810 |
[6]:
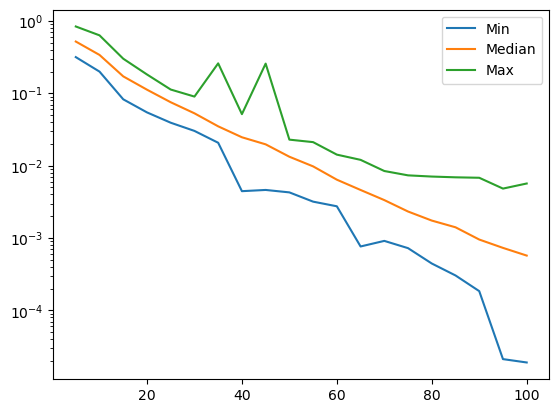
import matplotlib.pyplot as plt
# Plot the quartiles and median over generations
generations = stats_by_gen.index
plt.plot(generations, stats_by_gen['25%'], label="Q1 (25th percentile)")
plt.plot(generations, stats_by_gen['50%'], label="Median")
plt.plot(generations, stats_by_gen['75%'], label="Q3 (75th percentile)")
plt.yscale("log")
plt.xlabel("Generation")
plt.ylabel("KKTPM")
plt.title("KKTPM Statistics Over Generations")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()